微监控 海恩法则在业务运维中的实践应用——以瑞得恩智慧运维平台为例
在当今高度复杂、高度耦合的数字业务系统中,任何微小的隐患都可能演变为灾难性的故障。如何将事故消弭于未然,是业务运维的核心挑战。德国飞机涡轮机发明者帕布斯·海恩提出的“海恩法则”为此提供了深刻洞见:每一起严重事故的背后,必然有29次轻微事故、300起未遂先兆以及1000起事故隐患。将这一法则的精髓融入现代运维,特别是通过“微监控”体系,已成为提升系统稳定性的关键。瑞得恩智慧运维平台,正是这一理念的杰出实践者。
一、海恩法则的运维启示:从被动救火到主动防御
海恩法则的核心在于,事故并非孤立事件,而是一系列征兆和隐患累积的必然结果。传统的运维模式往往侧重于事故发生后的应急响应与故障恢复,即“救火式”运维。这种模式代价高昂且疲于奔命。而海恩法则启示我们,运维的重心必须前移,致力于发现并消除那“1000起隐患”和“300起先兆”。这意味着需要建立一个能够持续、细致、自动化地捕捉系统任何“不适”的监控体系——这正是“微监控”的价值所在。
二、微监控:构建感知隐患的神经网络
微监控,区别于传统关注核心指标(如CPU、内存使用率)的宏观监控,是一种更精细化、更立体的监控理念。它要求:
- 监控粒度更细:不仅监控服务与应用,更深入到每一次API调用、每一个关键函数、每一笔事务链路、每一个第三方依赖的响应。
- 监控维度更广:涵盖性能指标(时延、吞吐量)、业务指标(交易成功率、关键流程转化率)、用户体验指标(页面加载时间、操作流畅度)以及基础设施的细微波动。
- 监控实时性更强:能够实现秒级甚至毫秒级的数据采集与分析,让“先兆”无处遁形。
通过微监控,系统如同拥有了遍布全身的敏感神经网络,任何一丝异常波动都能被及时捕捉,为预警和干预提供宝贵的时间窗口。
三、瑞得恩智慧运维平台的实践:让法则融入平台血脉
瑞得恩智慧运维平台将海恩法则与微监控理念深度结合,构建了一套集“感知、洞察、预警、处置”于一体的主动式运维体系。
1. 全栈链路追踪与性能微感知
平台通过无侵入或低侵入的探针,对分布式应用进行全链路追踪。一次用户请求从前端到后端,经过哪些服务、调用哪些数据库、耗时几何、成功与否,全部清晰可视。任何环节的轻微延迟(哪怕是几十毫秒的增加)或错误率的微小攀升,都会被记录和分析,成为海恩法则中的“未遂先兆”。
2. 智能基线学习与异常检测
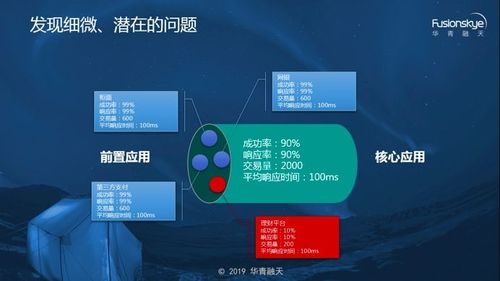
平台运用机器学习算法,为每项监控指标建立动态基线(如每日、每周的业务规律)。系统不仅能发现绝对值异常(如错误数>10),更能敏锐识别“相对异常”——即指标偏离其历史正常行为模式的情况。例如,平日凌晨1点数据库查询耗时平均50ms,某天突然持续稳定在80ms,虽未超阈值,但已被平台标记为“隐患”,触发根因分析。这正是对“1000起隐患”的自动化挖掘。
3. 关联分析与根因定位
当出现异常告警时,平台并非孤立看待。它会自动关联同一时段的基础设施监控、日志事件、变更记录等信息。例如,应用响应变慢,平台能快速关联到是某一台宿主机底层磁盘IO异常所致,或是某次近期发布的代码变更引入的性能衰退。这帮助运维人员直达问题本源,有效处置“轻微事故”,防止其叠加放大。
4. 预测性预警与容量规划
基于历史数据与趋势分析,平台能够预测系统潜在的风险点。例如,通过对业务增长趋势和资源消耗模型的拟合,提前预警数据库容量将在两周后达到瓶颈,推动扩容操作在“隐患”阶段完成,避免演变为“事故”。
四、实践价值:从量化到质变的运维效能提升
通过引入海恩法则指导下的微监控实践,瑞得恩智慧运维平台为用户带来了显著价值:
- 故障预防率大幅提升:超过80%的潜在严重故障在“先兆”或“隐患”阶段被提前发现和干预。
- 平均故障修复时间(MTTR)显著降低:精准的根因定位将排查时间从小时级缩短至分钟级。
- 运维模式根本性转变:团队从被动的“消防员”转变为主动的“系统健康管理师”,专注于优化与改进。
- 业务连续性保障增强:极致的稳定性和可预测性,为业务创新与发展奠定了坚实的技术基石。
###
海恩法则揭示了安全的本质在于对细节的敬畏与把控。在数字化转型的深水区,瑞得恩智慧运维平台通过构建深度融合海恩法则的微监控体系,将这种把控力赋予了每一个运维团队。它不仅仅是一个工具平台,更代表了一种先进的、以预防为核心的运维哲学。在微监控的“慧眼”之下,隐患无所遁形,先兆皆成预警,从而真正构筑起数字业务坚不可摧的稳定性防线。
最新产品